Data, Science, & Librarians,
Oh My!
My thoughts as I navigate the world of data librarianship.
So. Many. Conferences.
My first two weeks of May have been just explicitly devoted to conferences. Planning, executing, attending, surveying -- you name it, I've been doing it in relation to some event or another. It's actually been great, but so exhausting. I am definitely giving a lot of props to event planners for doing this as their day-to-day.
NYU Reproducibility Symposium
My first time organizing a conference-ish thing! I helped to organize the 2016 NYU Reproducibility Symposium which took place May 3, 2016 in the Jacob's room of The Center for Urban Science + Progress. This was an initiative of the The Moore-Sloan Data Science Environment at NYU. We put a call out for lighting talks and demos, and the response we received from the NYU community and beyond was really great! We ended up putting together a fairly diverse schedule packed with folks who work in fields like computer science, psychology, libraries, physics, maths, and more.
The point of the day was to showcase tools to help make the reproducibility process easy, along with case studies showing how creating reproducible experiments has helped other research groups. We had a great turn out across the MSDSE. Our partners UC Berkeley and University of Washington made up 11% of the registrations and 33% of the speakers.
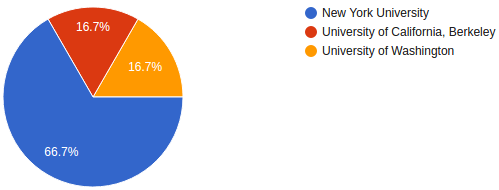
A breakdown of the institutional affiliation of the Symposium. I generated this via Google Forms.
The people who registered were also pretty diverse. The top 5 positions who had the most registrations:
- Faculty
- Doctoral Candidate
- Masters Student
- Postdoc
- Staff or Adminsitrator
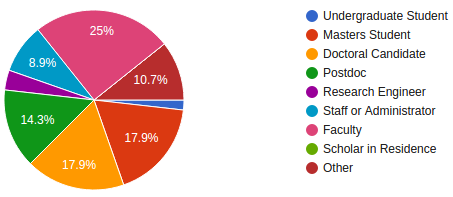
A breakdown of the status of those registered for the Symposium. I generated this via Google Forms.
We ended up deviating a bit from the schedule; we had all our lightning talks (with a few coffee breaks and a brown bag lunch) and in place of the breakout sessions in the afternoon, we ended up having a rountable discussion based on the participants vote. We gathered around the table to discuss some hands-on strategies for things like the best way to change the rewards systems to encourage openness and reproducibility (promotion/tenure, publishing, etc.), teaching reproducibility concepts, and culture hacking (thanks to Philip Stark for this one). The last session was a panel, which I unfortunately had to miss to head out to another conference...

A photo I took of our roundtable!
Big props also to my fellow organizers:
- Juliana Freire, Professor of Computer Science and Engineering and Data Science; Executive Director, NYU Moore-Sloan Data Science Environment
- Dennis Shasha, Professor of Computer Science, Courant Institute of Mathematical Sciences, NYU
- Kyle Cranmer, Associate Professor of Physics, NYU College of Arts and Sciences
- Fernando Chirigati, PhD Student, NYU Tandon School of Engineering
- Remi Rampin, Research Engineer, NYU Tandon School of Engineering
- Margaret Smith, Physical Sciences Librarian, NYU Division of Libraries
RDAP
So, I actually had to leave the Reproducibility Symposium early to make my way down to Atlanta, GA for my first ever RDAP Summit! It had a great program stacked with leaders in the field of data management, repository management, and other roles related to researchers and their data. From the RDAP website: "The Summit is relevant to the interests and needs of data managers and curators, librarians who work with research data, and researchers and data scientists. A wide range of disciplines from the life sciences, physical sciences, social sciences, and humanities will be represented. The Summit will bring together practitioners and researchers from academic institutions, data centers, funding agencies, and industry." A lot was covered from a lot of different perspectives--my favourite panel for this was kind of unexpected. Panel 5: "Data Management Plans and Public Access: Agency and Data Service Experiences" had an incredible selection of panelists -- one person from the DOE, one from NSF (division of biological infrastructure), one from NIH, and one librarian at an academic university. I loved this panel because the audience got to hear the status of DMPs right from the source -- the federal agencies. There was a lot of discussion about auditing DMPs, budgeting for RDM, and repositories for data deposit. It was absolutely great.
A minor but very important reason for my attendance at this year's RDAP Summit was because I had a poster accepted! My co-author Kevin Read was able to go with me, but our other co-author Drew Gordon had to miss it. We got a lot of interesting questions -- our poster was essentially displaying some work we have done and continue to do to bridge the gaps across the vast NYU campuses and researchers to deliver better and more coordinated data services. Check it out:
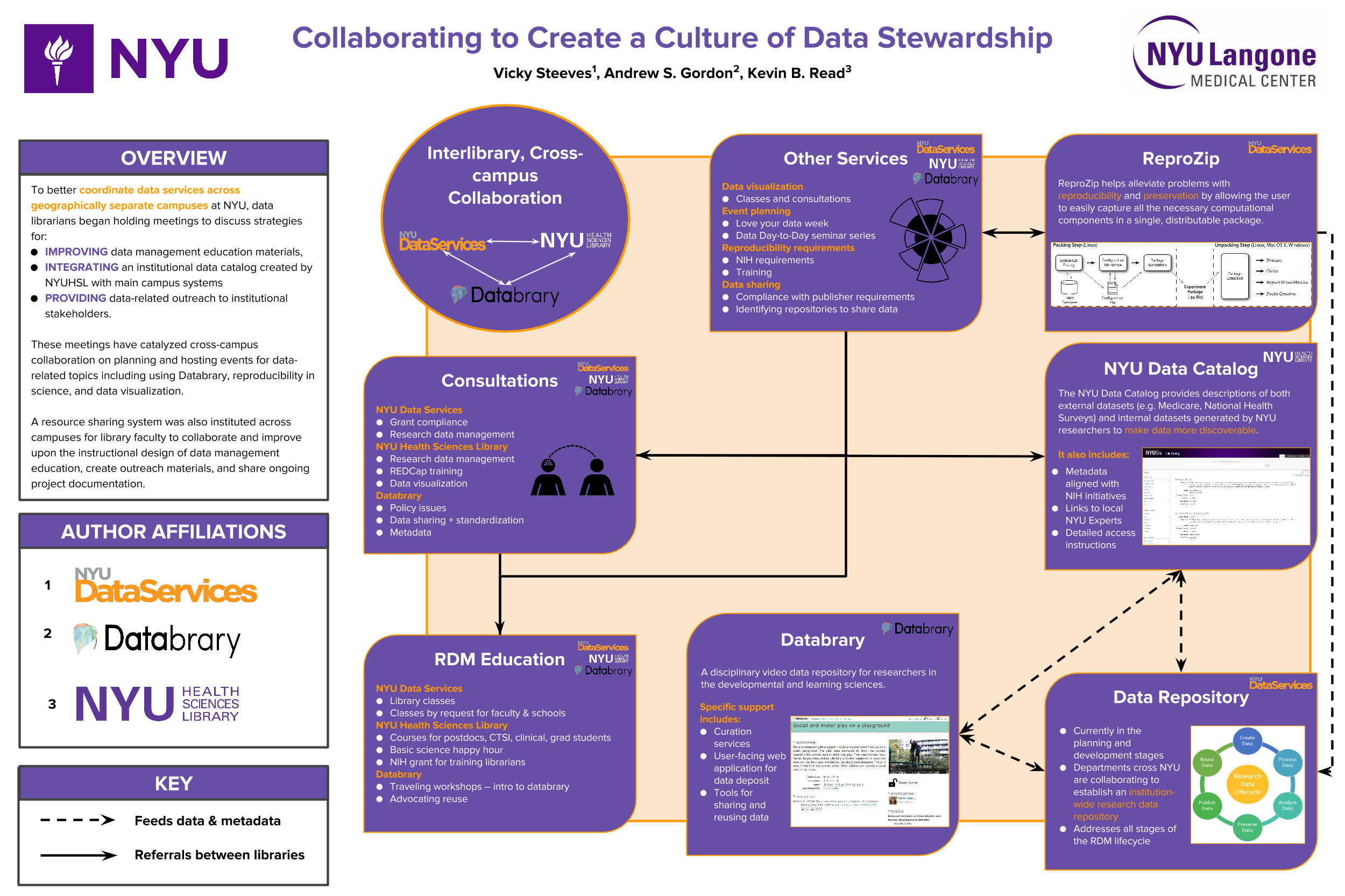
"Collaborating to Create a Culture of Data Stewardship" – Vicky Steeves, Kevin Read & Drew Gordon
DASPOS
My last conference of May was the Container Strategies for Data and Software Preservation Workshop, a two day workshop organized by the NSF-funded Data and Software Preservation for Open Science (DASPOS) project, hosted at the University of Notre Dame.
I served as an external organizer, and Rémi & I (we're super cute and have a joint speaker bio) had one large demo + presentation, and then ran three separate breakout sessions, all for ReproZip. ReproZip is an open source software developed at NYU that seeks to lower the barrier of making research reproducible. ReproZip allows researchers to create a compendium of their research environment by automatically tracking programs and identifying all their required dependencies (data files, libraries, configuration files, etc.). After two commands, the researcher ends up with a neat archived package of their research that they can then share with anyone else, regardless of operating system or configuration. These community members can unzip the package using ReproUnzip, and reproduce the findings.
@remram44 & I are presenting #ReproZip today @ #DASPOS workshop on container. sci! Lowering the barrier to #repro: https://t.co/3wDCu5XsvE
— Vicky Steeves (@VickySteeves) May 19, 2016
The DASPOS organizers used the Open Science Framework to organize all the conference materials such as notes, presentations, code, videos, whatever people wanted to contribute. For our breakouts, we had a separate ReproZip OSF component to take notes and centralize materials and accompanying GitHub repro where people could deposit any examples or use-cases. And we actually got one! Bertini is a a package for solving polynomial systems, developed at Notre Dame in the math department. The ReproZip package was deposited into our ReproZip OSF con. The depositor has made a great README with instructions and also provided a .rpz package so others can reproduce his work!
The last day of the workshop I was invited to sit on a panel--which was the last session of the whole thing! Here are some notes summarizing what was said -- ultimately, I went kinda punk rock about reproducibility, as I always do. Some key quotes of mine include:
- "Your science doesn't belong to you" -- this one got a lot of attention from the researchers in the room...
- "If you have to spend 3 months cleaning up your data or code before you publish it [following a journal publication], then why should I trust your paper?" -- I got crickets with this one...no one said a word until the next question...
- "Science no longer requires evidence. This is an ideal we need to return to as a general body." -- this prompted some debate about the role of publishers in promoting open science...
And of course, the one stolen one from Philip Stark:
.@philipbstark 's "hacking the culture" quote has now made its way into all my convos about #reproducibility #quoteparasite
— Vicky Steeves (@VickySteeves) May 19, 2016
The organizers said they would release all the videos, transcripts, and other A/V related materials as soon as possible, which is great. What I love is that DASPOS walks the walk: all the presentations are available for people to look at, download, critique, whatever, along with the rest of the conference materials. Everything was done in the open! We just have to containerize our OSF for Meeting space ;)